
前段时间,12月末的时候,组长给我分配了一个 对主题分类的新上线实例进行标记 的需求。因为组里我这块确实没啥活了,剩下的都是一些评审会没开完,或者是实现起来比较困难的需求。但当时实在没事干,想多搞点产出写简历上(当时我还期盼着春招能进大厂实习,现实把我的幻想击成粉碎),然后就给我排了这个活。
因为逻辑很复杂,干了一天,搞出来第一版能跑的代码,然后回学校准备期末考试了,一回就是半个月,到1.12号才回来上班,review完发现我写的实在是依托,然后这个礼拜对这个需求时不时改改改,从最开始的沿用项目的DDD设计模式,到MVC,到最后MVC+沿用责任链的设计模式,所以这次复盘,把所有能回忆起来的踩过的坑都写出来。哎,贴一下我的git记录。还是太几把菜了。
看上去很简单,对新上线的某个分类下的实例进行标记,多弄一个po搞一张表,存储新上线的这个实例,到时候返回给前端的时候直接返回能带这个数据的vo就行
第一版
开始看需求的时候发现完全不是这么回事。首先这个需求在前端需要展示的地方是一棵树,在树上的节点上进行new的标记。原始需求的需求长这样

并且发现这个树并不是每个新上线的实例作为节点的树,而是分类的树。实例是属于某一个分类的,所以最终要标记的还是分类树的节点。有专门的实例与分类关联的表。
那么新上线的实例从何而来,该怎么判断呢?这个项目中,实例是跟任务相关的。实例是由一个个任务组成的,当对应的任务上线时候,对应的实例也会上线。因此,就需要找到任务上线的那一块代码,在任务上线的时候,判断这个任务是不是新上线的,是的话找到对应的实例,再找到对应的分类,把这个有新上线的实例的分类用一张表存储起来。然后给前端返回这棵树的时候,通过这张表的数据在vo上多加一个字段进行标记,这个是路径上的还是目标节点的树节点,让前端进行渲染。
然后开始理这些表的关系:
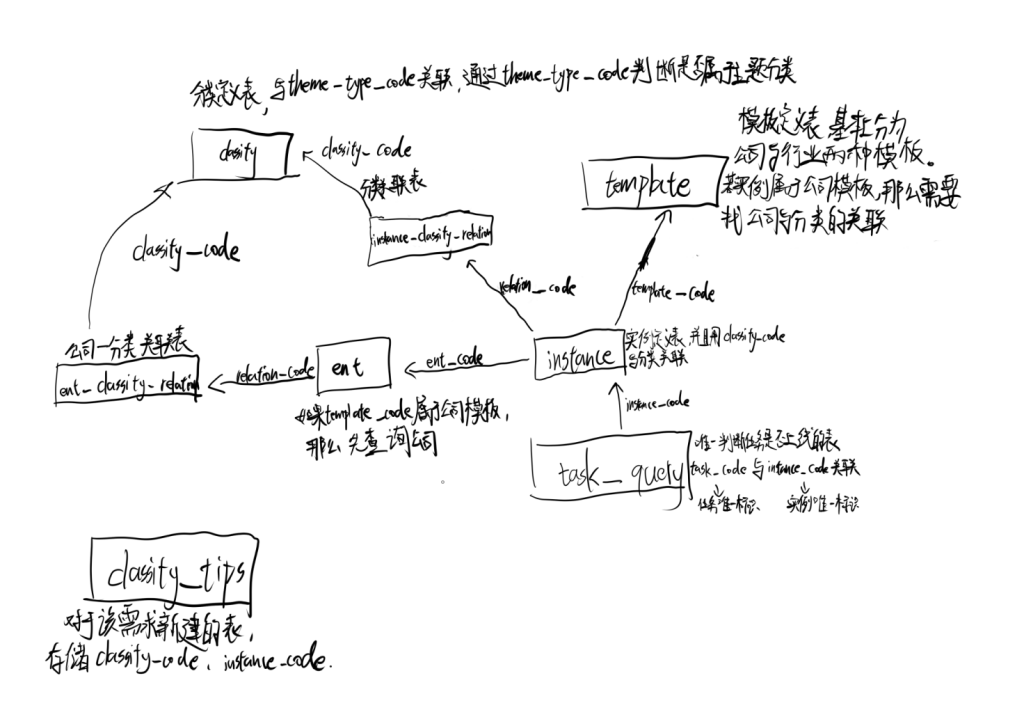
大致的表的关系如上,同时也理清了查询的逻辑。然后开始写代码.
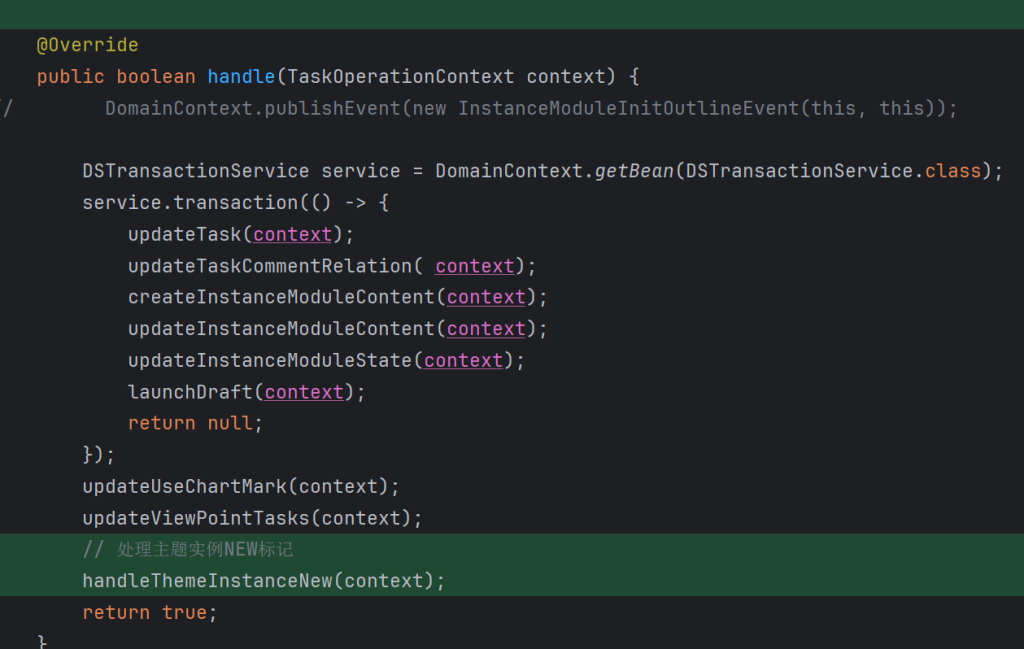
首先是任务上线时的判断+存储功能,在原来责任链下多加一个处理主题分类下实例的处理器,然后在这个处理器下面写代码,并且沿用DDD模式,对这张新表的po tpl po entity都放在domain包下。但是此时这一版根本没用到这些entity之类,仅仅用到repo对数据库操作的封装。
大概得伪代码就是,先查询传进来这个需求的taskCodes,对taskCodes找到对应的InstanceCode和对应的templateCode,对能展示的templateCodes进行过滤,分为行业模版下和公司模版下的 instanceCode与taskCodes的映射,然后分为不同的逻辑去查表,返回对应的有效的classifyCodes。
查询instanceCode对应的classifyCode的时候,因为是多对多的关系,一个instanceCode可能对应多个classifyCode,并且这些classifyCode,能构成树的关系,通过parrent_classify_code字段进行标识,那么这个时候就取第一棵树的最深的子节点,作为这个instanceCode的classifyCode。下面贴一下我对classifyCodes的树的构建和取第一棵树最深的子节点的代码:
/**
* 对于每个实例的多个分类,取第一棵树的最深子节点
*/
private Map<String, String> findDeepestClassifyForInstances(
List<?> relations, // ResearchInstanceClassifyRelationPo 或 InstanceClassifyRelation
List<ListedCompanyClassifyPo> classifies) {
// 建立分类的父子关系映射
Map<String, List<String>> parentToChildrenMap = new HashMap<>();
Map<String, ListedCompanyClassifyPo> classifyMap = new HashMap<>();
for (ListedCompanyClassifyPo classify : classifies) {
classifyMap.put(classify.getClassifyCode(), classify);
String parentCode = StringUtils.isBlank(classify.getParentClassifyCode()) ? "ROOT" : classify.getParentClassifyCode();
parentToChildrenMap.computeIfAbsent(parentCode, k -> new ArrayList<>())
.add(classify.getClassifyCode());
}
// 按实例分组
Map<String, List<String>> instanceToClassifiesMap = new HashMap<>();
for (Object relation : relations) {
String instanceCode;
String classifyCode;
if (relation instanceof ResearchInstanceClassifyRelationPo) {
instanceCode = ((ResearchInstanceClassifyRelationPo) relation).getInstanceCode();
classifyCode = ((ResearchInstanceClassifyRelationPo) relation).getClassifyCode();
} else if (relation instanceof InstanceClassifyRelation) {
instanceCode = ((InstanceClassifyRelation) relation).instanceCode;
classifyCode = ((InstanceClassifyRelation) relation).classifyCode;
} else {
continue;
}
instanceToClassifiesMap.computeIfAbsent(instanceCode, k -> new ArrayList<>())
.add(classifyCode);
}
// 对每个实例,找到第一棵树的最深叶子节点
Map<String, String> result = new HashMap<>();
for (Map.Entry<String, List<String>> entry : instanceToClassifiesMap.entrySet()) {
String instanceCode = entry.getKey();
List<String> classifyCodes = entry.getValue();
if (classifyCodes.isEmpty()) {
continue;
}
// 找到所有顶级分类(没有父分类或父分类不在当前集合中)
Set<String> currentClassifySet = new HashSet<>(classifyCodes);
List<String> topClassifies = new ArrayList<>();
for (String code : classifyCodes) {
ListedCompanyClassifyPo classify = classifyMap.get(code);
if (classify == null) {
continue;
}
String parentCode = classify.getParentClassifyCode();
if (StringUtils.isBlank(parentCode) || !currentClassifySet.contains(parentCode)) {
topClassifies.add(code);
if (!result.containsKey(instanceCode)) {
// 保存第一棵树的根节点
result.put(instanceCode, null); // 先占位,稍后更新为最深节点
}
}
}
if (topClassifies.isEmpty()) {
// 如果没有找到顶级分类,取第一个
result.put(instanceCode, classifyCodes.get(0));
continue;
}
// 从第一棵树的根节点开始,找到最深的叶子节点
String firstRoot = topClassifies.get(0);
String deepestLeaf = findDeepestLeaf(firstRoot, parentToChildrenMap);
result.put(instanceCode, deepestLeaf);
}
return result;
}
/**
* 递归查找树的最深叶子节点(取最后访问的叶子节点)
*/
private String findDeepestLeaf(String rootCode, Map<String, List<String>> parentToChildrenMap) {
String deepest = rootCode;
Queue<String> queue = new LinkedList<>();
queue.offer(rootCode);
while (!queue.isEmpty()) {
String current = queue.poll();
List<String> children = parentToChildrenMap.get(current);
if (children != null && !children.isEmpty()) {
for (String child : children) {
queue.offer(child);
}
} else {
// 是叶子节点
deepest = current;
}
}
return deepest;
}有点啰嗦,因为当时是写完一遍之后边调试边改,能跑通就放一边了。然后拿到所有的instanceCode和classifyCode的映射之后,进行持久化的逻辑。因为保存的表永远只保存五条标记为new的classifyCode的数据,因此要先过滤五条映射出来,然后进行更新。更新的逻辑有两种,如果原来表中有对应的classifyCode,那么对那条数据进行更新update_at字段;如果没有,那么取update_at最早的那些数据进行判断。
到此为止,主题分类下新实例的信息已经保存好了,之后就是给前端返回那棵树的时候进行节点标记。原来返回的树的每一个节点是一个vo,controller返回的是这个List<vo>,并且每个vo拥有一个List<vo> children的字段,所以能返回一棵树。我的第一想法是直接在原来这个vo上加一个newFlag字段,此时的我完全没有考虑到业务的入侵,这棵树是会存储到redis中的,到时候我本地服务对redis的这个Key更新的时候,会多加一个field,导致在测试环境中的redis与测试环境的后端代码反序列化不一致,测试环境就炸了。原来的代码已经获取了这棵树,那我只要查询我新建的这张表中的数据,然后对这棵树进行目标节点的搜索和New标记,还有路径上的标记。代码如下:
public CompanyCommonTreeVo themeTree() {
List<IndustryTreeNodeVo> tree = listedCompanyClassifyService.treeOnline(themeTypeCode);
// 处理NEW标记
// 1. 获取t_research_theme_instance_new中的五条数据中的instanceCode
List<String> instanceCodeList = researchThemeInstanceNewRepository.getTop5OrderByUpdateTime().stream()
.map(po -> po.getInstanceCode())
.collect(Collectors.toList());
if (!CollectionUtils.isEmpty(instanceCodeList)) {
// 2. 获取instanceCode对应的classifyCode
List<String> classifyCodeList = researchThemeInstanceNewRepository.getClassifyCodesByInstanceCodes(instanceCodeList).stream()
.distinct()
.collect(Collectors.toList());
// 3. 在tree中递归遍历找到对应的classifyCode节点,标记路径
// 目标节点置为2,路径上的节点置为1,且更新时判断,1可以变为2,2不能变为1
markTreeNodesWithNewFlag(tree, classifyCodeList);
}
CompanyCommonTreeVo vo = new CompanyCommonTreeVo();
vo.setTreeList(tree);
vo.setTypeCode(themeTypeCode);
return vo;
}
/**
* 递归标记树节点的NEW标记
* 目标节点置为2,路径上的节点置为1
* 更新规则:1可以变为2,2不能变为1
*
* @param tree 树节点列表
* @param targetClassifyCodes 目标分类代码列表
*/
private void markTreeNodesWithNewFlag(List<IndustryTreeNodeVo> tree, List<String> targetClassifyCodes) {
if (CollectionUtils.isEmpty(tree) || CollectionUtils.isEmpty(targetClassifyCodes)) {
return;
}
// 使用Set提高查找效率
Set<String> targetCodeSet = new HashSet<>(targetClassifyCodes);
for (IndustryTreeNodeVo node : tree) {
markTreeNode(node, targetCodeSet);
}
}
/**
* 递归标记单个节点及其子节点
* 返回是否在路径上找到了目标节点
*
* @param node 当前节点
* @param targetCodeSet 目标分类代码集合
* @return 是否在路径上找到了目标节点
*/
private boolean markTreeNode(IndustryTreeNodeVo node, Set<String> targetCodeSet) {
if (node == null) {
return false;
}
boolean isTarget = targetCodeSet.contains(node.getClassifyCode());
boolean foundInChild = false;
// 先递归处理子节点
if (!CollectionUtils.isEmpty(node.getChildren())) {
for (IndustryTreeNodeVo child : node.getChildren()) {
if (markTreeNode(child, targetCodeSet)) {
foundInChild = true;
}
}
}
// 根据规则设置newFlag
// 目标节点置为2,路径上的节点置为1
// 更新规则:1可以变为2,2不能变为1
Integer currentFlag = node.getNewFlag();
if (isTarget) {
// 目标节点直接置为2
node.setNewFlag(2);
} else if (foundInChild) {
// 在路径上,但不是目标节点
// 只有当当前标记不是2时才设置为1(2不能变为1)
if (currentFlag == null || currentFlag != 2) {
node.setNewFlag(1);
}
}
return isTarget || foundInChild;
}MVC架构修改
上面那一版能跑通,我就回学校准备期末考试了,一走就是半个月,回来的时候重新理了很久业务需求跟执行逻辑,然后发现基本上用不到DDD的架构,我domain层里的vo entity tpl 都没用到过,只有repo对mapper进行封装了一下,那我为啥还要用DDD呢,直接用MVC就好了,把上面全部删掉,repo也不要了,直接对mapper进行调用。
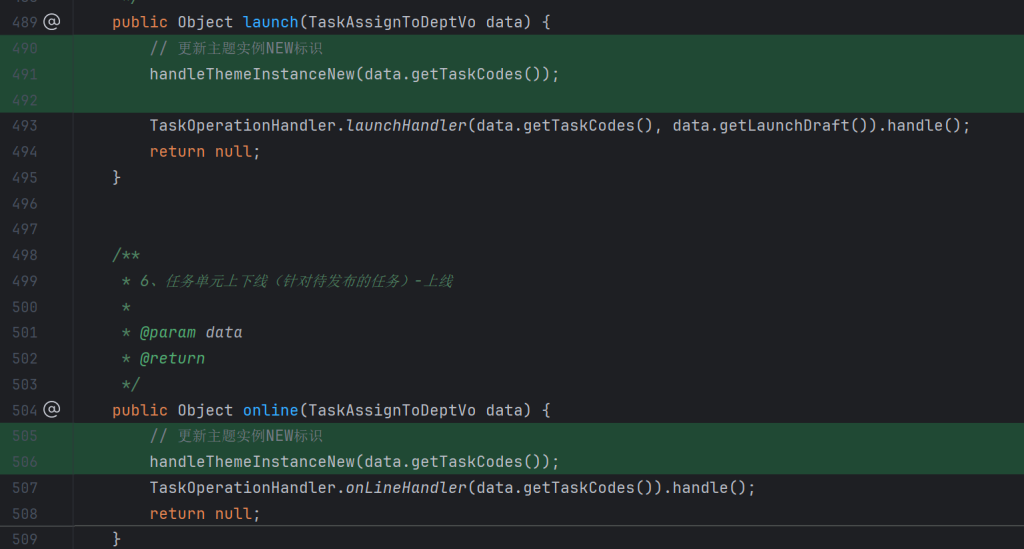
把这些处理逻辑全部放在service,然后在任务要上线的时候先进行new标记处理。
这里有一个很矛盾的点,首先就是事务的问题,没办法保证处理New标记的逻辑和真正上线的逻辑同时成功或者失败,直接给这两行代码加事务性能太差了,而且也不符合软件设计的原则,应该在持久层加事务而不是这里;
然后就是我把处理New标记的逻辑放在了真正上线逻辑的上面,这里是因为假如放在下面的话,那么是先上线,上线的数据已经入库了,在下面处理New标记的逻辑上对这个任务进行判断时,发现这个任务已所属的实例已经有上线的任务了,没办法判断这个实例是不是第一次上线,很纠结,所以这版肯定不行,还是要在责任链中加处理器去进行处理。
MVC+责任链
保持service中单单这一条的责任链,在责任链的持久化处理器之前,多加一个处理器,这个处理器收集所有需要保存到这张新表的数据,然后赋值给上下文context,之后的持久化的处理器中,从context拿到这个数据,在事务内进行保存。其中,这个保存的逻辑(判断是更新还是替换最早记录等等)放到对这张新表的业务的service中,通过service中的方法对mapper进行持久化调用。
当然,还有前面的那个vo多加字段造成反序列化失败的问题。这里我多加了一个vo,复制原来vo的所有字段并且加了newFlag字段,从原来的vo将值递归拷贝到新的vo,贴一下我的这段代码:
/**
* 递归转换节点
*
* @param source 源节点
* @return 转换后的新节点
*/
private IndustryTreeNodeNewVo convertNode(IndustryTreeNodeVo source) {
if (source == null) {
return null;
}
IndustryTreeNodeNewVo target = new IndustryTreeNodeNewVo();
BeanUtils.copyProperties(source, target);
// 递归转换子节点
if (!CollectionUtils.isEmpty(source.getChildren())) {
List<IndustryTreeNodeNewVo> newChildren = new ArrayList<>(source.getChildren().size());
for (IndustryTreeNodeVo child : source.getChildren()) {
newChildren.add(convertNode(child));
}
target.setChildren(newChildren);
}
return target;
}对原来的其它代码进行了一些优化,比如在找最深的叶子节点时,假如有这样两条脏数据,这两个节点互为父亲,那么会导致这个BFS不停地循环,所以加了一个深度迭代,一棵树高度最大是10,在这个业务中够用了:
/**
* 查找树的最深叶子节点
*/
private String findDeepestLeaf(String rootCode, Map<String, List<String>> parentToChildrenMap) {
String deepest = rootCode;
Queue<String> queue = new LinkedList<>();
queue.offer(rootCode);
// 定义最大深度限制 10
int maxDepth = 10;
int currentDepth = 0;
while (!queue.isEmpty() && currentDepth < maxDepth) {
int levelSize = queue.size();
// 按层处理
for (int i = 0; i < levelSize; i++) {
String current = queue.poll();
List<String> children = parentToChildrenMap.get(current);
if (children != null && !children.isEmpty()) {
queue.addAll(children);
} else {
// 没有子节点时,更新deepest
deepest = current;
}
}
currentDepth++;
}
return deepest;
}还有对实例与分类映射的森林中找到每个森林的root节点时,剔除所有的存在parrentClasifyCode,但是parrentClasifyCode的不属于能展示的分类的森林的根节点,相当于直接去掉这棵树,一般真实的场景下是不会有这棵树的。
逻辑中需要主题分类的themeTypeCode,我最开始直接用Environment.class从配置文件中获取,组长跟我说项目后续部署在docker上时这样做不是很规范,涉及到docker的环境变量和Spring中Environment搜寻配置信息的优先级的问题。然后让我从一个已经注入的Bean,并且这个Bean同时注入了配置文件中的这个信息的类中去获取themeTypeCode。其实我也不是很懂,可能是为了健壮性吧,毕竟@Value和Environment.class.getValue本质上是一样的。
